


To build a good Machine Learning model, Feature Engineering is a crucial step. During Data Preprocessing, we do feature engineering so that our data will be perfect for the model-building. Feature Engineering includes many scaling techniques such as Standardization and Normalization. Because of this, the data will be on the same scale. As a result, the model performance will increase. Keep reading the article, to get a detailed understanding of Normalization and Standardization.
What is Normalization?
Normalization is a scaling technique in which the values are shifted and scaled in the range of 0 to 1.
Formula:
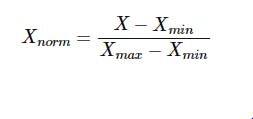
What is Standardization?
Standardization is another scaling technique in which the values are scaled in a uniform way. The values are centered around the mean. We apply the z-score formula here. As a result, the mean becomes 0 and the standard deviation becomes 1. Note that, there is no particular range in the case of Standardization.
Formula:
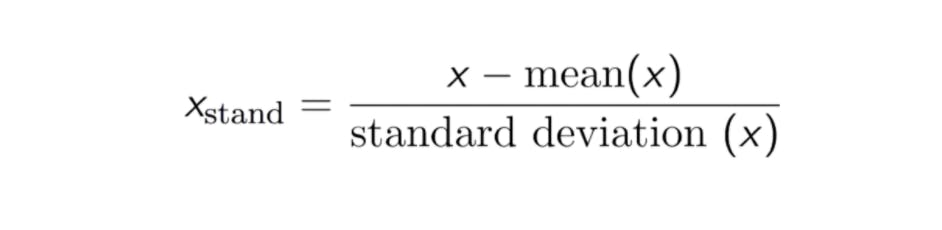
Normalization vs Standardization
| Normalization | Standardization |
| Values are scaled in the range of 0 to 1. | Values are centered around the mean. The standard deviation becomes 1. |
| Affected by Outliers. | Robust to Outliers. |
| The shape of the original distribution will not change. | It changes the shape of the original distribution. |
There is no clear-cut rule to say where to use Normalization or where to use Standardization. In the end, it depends on your problem statement and the dataset. You can try using raw data, and both the Normalized and standardized data in the Machine Learning Model to check where the model performs the best.
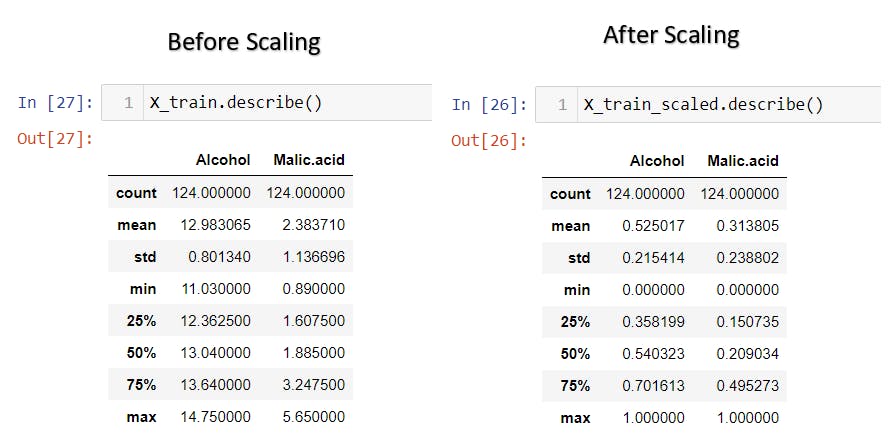
Normalization using Python code
The sklearn (scikit-learn) library offers MinMaxScaler for Normalization.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# fit the scaler to the train dataset
scaler.fit(X_train)
# transform both train and test datasets
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
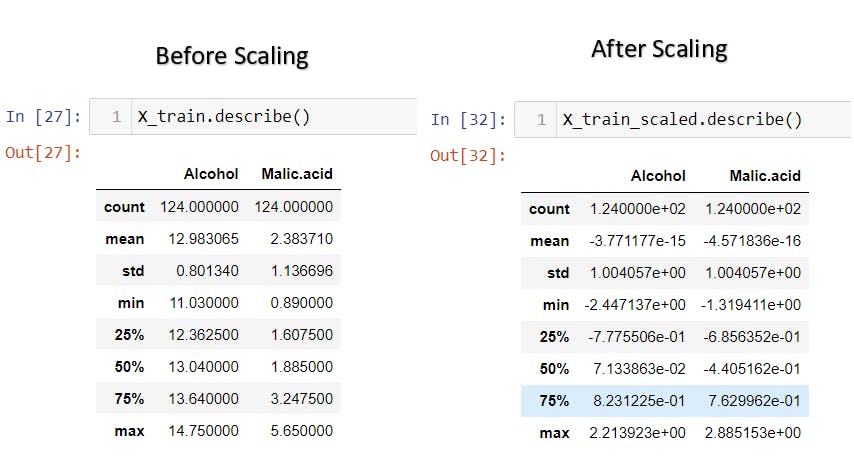
Standardization using Python Code
The sklearn (scikit-learn) library offers StandardScaler for Standardization.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# fit the scaler to the train dataset
scaler.fit(X_train)
# transform both train and test datasets
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
Jupyter Notebook:
https://github.com/ShowRounak/Python-Basic/blob/main/Normalization%20and%20Standardization.ipynb