


Introduction:
Machine learning algorithms have revolutionized the way we extract insights and make predictions from vast amounts of data. However, an important challenge that practitioners face is the phenomenon of overfitting. Overfitting occurs when a model learns to perfectly fit the training data but fails to generalize well to unseen data. In this blog post, we will explore the concept of overfitting, its causes, and techniques to mitigate its effects.
Understanding Overfitting:
Overfitting arises when a model becomes excessively complex, effectively memorizing the noise and idiosyncrasies of the training data rather than capturing the underlying patterns. As a result, the overfitted model performs poorly when faced with new, unseen data, rendering it unreliable and ineffective for real-world applications.
Let's understand this with an example:
Imagine you have a friend named Robbie who loves puzzles. One day, Robbie gets a new puzzle with lots of pieces to put together. He starts working on it and tries to fit each piece in its proper place.
Now, imagine that instead of using his eyes to see which pieces fit, Robbie starts to memorize the shapes and colors of each piece. He spends a lot of time trying different combinations until all the pieces fit together perfectly.
When Robbie finishes the puzzle, he is very proud because it looks exactly like the picture on the box. But here's the tricky part: what if Robbie gets another puzzle with a similar picture but different shapes and colors? He may find it challenging to put the pieces together because he memorized the previous puzzle's specific details.
This is similar to what happens with overfitting in machine learning. Instead of truly understanding the patterns in the data, the model tries too hard to memorize every detail from the training examples. Just like Robbie, the model fits the training data perfectly, but it may struggle when faced with new, unseen data because it focused too much on the specific examples it learned from.
Causes of Overfitting:
Insufficient Training Data: When the available training data is limited, models may struggle to learn meaningful patterns, leading to overfitting.
Model Complexity: Highly complex models with numerous parameters, such as deep neural networks, are prone to overfitting as they can easily adapt to noise in the data.
Feature Overload: Including irrelevant or redundant features in the training data can confuse the model and cause it to overfit.
Overfitting with Bias-variance Trade-off:
Overfitting occurs when there is a high variance in the model, meaning it captures too much of the noise present in the training data. The model becomes too complex, closely fitting the training data, but fails to generalize well to new data.
In the bias-variance tradeoff, bias represents the model's underfitting, while variance represents its overfitting. The goal is to find the right balance between the two. Models with low bias and low variance strike this balance by capturing the underlying patterns in the data while avoiding overfitting. However, achieving this balance is often challenging.
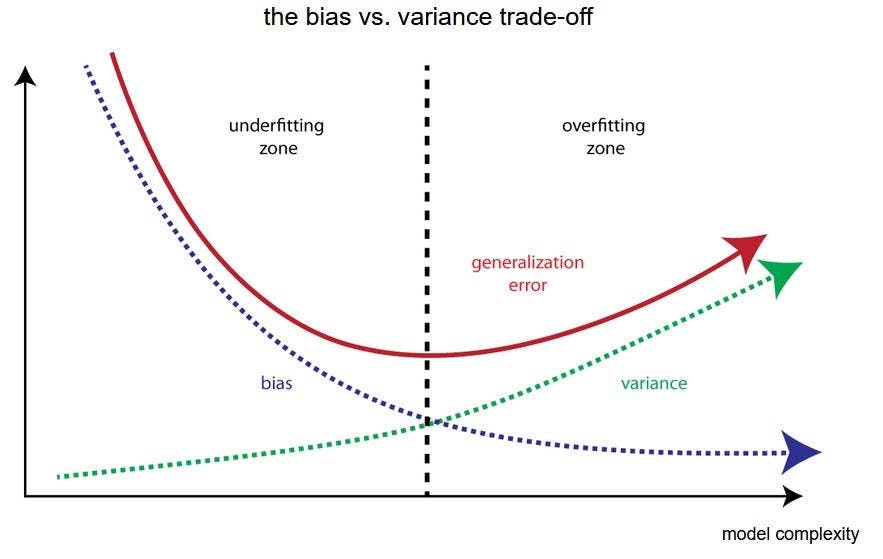
To read more about this, follow the link: '**The intuition behind bias and variance**' - Seth Mottaghinejad
Preventing and Mitigating Overfitting:
Cross-validation: Apply techniques like k-fold cross-validation to assess model performance on multiple subsets of the data, providing a more robust evaluation.
Regularization: Apply regularization techniques, such as L1 and L2 regularization.
Feature Selection: Carefully choose relevant features and remove unnecessary ones to improve the model's ability to generalize.
Conclusion:
Overfitting is a common pitfall in machine learning, and it poses a significant challenge for practitioners. Understanding its causes and consequences is crucial to building reliable models that generalize well to new data. By employing techniques like cross-validation, regularization, and feature selection, we can strike a balance between model complexity and generalization, ensuring the effectiveness and practicality of our machine learning solutions.
My LinkedIn: https://www.linkedin.com/in/rounak-show-211131174/
My GitHub: https://github.com/ShowRounak